
结论先行:浏览器自动化工具已超过50个,但底层只有6条技术路线——CDP直控、无障碍树、截图识别、云浏览器、反检测、AI原生。选对路线,500 Token能搞定的事,选错就要烧5万。差距不在工具好坏,而在架构设计。
本文不评价具体工具优劣,而是拆解每条路线的底层运行机制。搞懂架构,你自己就能判断新工具的能力边界。

路线一:CDP直控——最底层的浏览器控制协议
CDP全称Chrome DevTools Protocol,是Chromium系浏览器的远程控制协议。你按F12打开开发者工具时,浏览器内部就在用这个协议通信。
自动化工具的做法很简单:建立一条WebSocket连接,连上浏览器的调试端口,发送CDP命令,浏览器执行后把结果返回。CDP定义了100多个Domain,每个Domain下有几十个Method,能力覆盖页面控制、DOM操作、网络拦截、JavaScript执行。这就是CDP路线工具能力如此强大的原因——它拿到的是浏览器最底层的控制权。

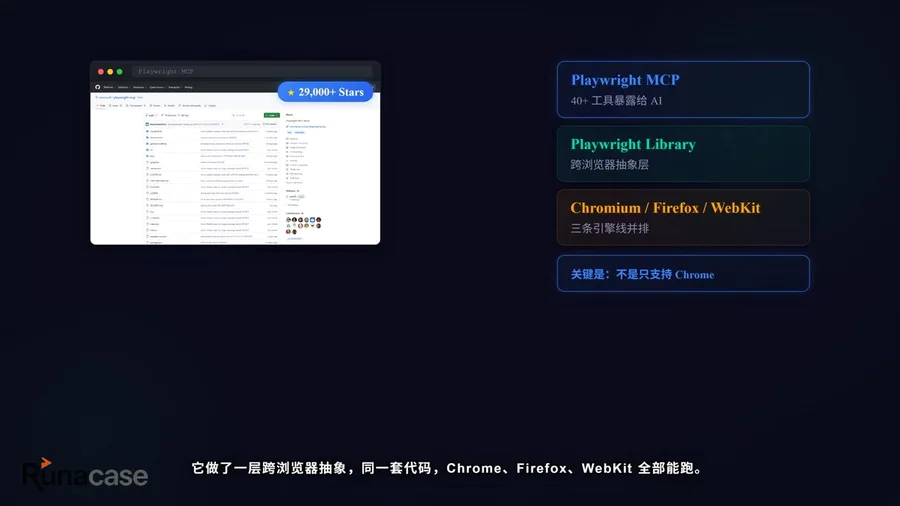
Playwright MCP:2026年的事实标准
基于CDP的工具中,Playwright MCP是当前的事实标准,29K+ Star,微软官方维护。它的核心能力是40多个标准化工具,AI调用一个工具就能完成一次页面操作。
- 不只是包了一层CDP,还做了浏览器抽象——同一套代码可跑Chromium、Firefox、WebKit
- Puppeteer只支持Chromium,Playwright把底层协议差异全部抹平
- 这个设计决策直接决定了它的适用范围远大于Puppeteer
同一路线的不同切入口
- Puppeteer:Google出品,只支持Chromium,更轻更快,但Anthropic已在2026年3月官方归档,推荐迁移到Playwright
- DevTools MCP:Google出品,走调试路线,Lighthouse审计、性能追踪、网络拦截是Playwright做不了的,代价是工具定义就要18K Token
- Browser Tools MCP:聚焦DevTools视角,抓控制台日志、网络请求、性能指标
- EA Automation MCP Playwright:主打设备模拟,143种设备配置开箱即用
同一条路线,不同工具选择了完全不同的切入口。

路线二:无障碍树——把Token成本压100倍
AI拿到浏览器控制权后,怎么"看"页面?这是第二条路线要解决的问题。
浏览器本身会为屏幕阅读器维护一棵无障碍树(Accessibility Tree),里面记录每个元素的角色、名称、状态。比如一个按钮,树里记录的是:角色button、名称"提交"、状态可点击。这棵树是纯文本的,一个页面大约500到2000 Token。
Playwright MCP默认就读这棵树,不走截图,不走DOM,所以Token成本控制得极好。

路线三:截图识别——能力强但成本高
第三种看页面的方式是截图识别:截一张页面图片,喂给多模态模型,让它判断该点哪里。
- 图片Token太贵,一张截图轻轻松松5万Token,操作10次就是50万
- 坐标点击直接算元素位置去点,不贵,但页面布局一变就全废
所以2026年的事实标准是无障碍树,不是因为它能力最强,而是性价比碾压。500 Token搞定的事,为什么要花5万?

路线四:云浏览器——解决"在哪里操作"
前三条路线解决的是"怎么操作浏览器",后三条解决的是完全不同的问题。
本地跑浏览器,IP固定、环境不变,跑多了网站直接封你。云浏览器把Chrome搬到云端,每次启动一个全新实例,IP随机分配,用完就销毁。
- Browserbase:高端路线,深度集成Stagehand自然语言交互,Bug0约0.15美元/小时,给标准CDP接口,代码不用改
- Browserless:起步价200美元/月,面向企业
选哪个取决于你的预算和规模。
路线五:反检测——要在C++层面做才有用
网站怎么发现你是机器人?四层检测:
- 第一层:TLS握手指纹,不同浏览器引擎的握手特征不一样
- 第二层:Canvas渲染指纹,让浏览器画一张图,像素级差异就能识别
- 第三层:查WebDriver标志位,自动化工具会留下标记
- 第四层:分析鼠标轨迹,太规律就是机器人
大部分反检测工具止步于第三层,因为它们用JavaScript改指纹,网站一查就知道你改过。Camoufox不一样,它基于定制版Firefox,直接在C++层面修改指纹数据,JavaScript层面根本查不出来。Actionions走垂直路线,专门做X平台自动化,关注、点赞、评论全自动。
路线六:AI原生——把选择器维护成本降到0
AI原生是2026年最热的一条路线。传统方式你得写选择器:"点击class为submit-btn的按钮",页面一改版选择器就废了。AI原生的思路是——你只说"点击提交按钮",LLM自己去页面里找,找错了还有自愈机制,换个选择器再试。
代表工具的不同侧重
- Stagehand:2026年2月做了V3完整重写,架构从DOM解析切换到CDP直连。以前要解析整个DOM树,现在直接跟浏览器对话,可靠性和速度都提升一大截
- Browser-AI:内置子代理,需要操作浏览器时把任务分发给子代理,主模型上下文不会因页面内容而膨胀
- Crawlee:31K Star的反检测爬虫,不走MCP路线,自己实现指纹轮换和自适应选择器,给它一个URL就能持续适应页面结构变化
这几个工具的共性是把LLM的理解能力嵌进了操作循环,但侧重点各不相同——有的侧重控制,有的侧重抓取。
MCP协议在体系中的角色
一句话:MCP是AI模型和浏览器之间的标准接口。
没有MCP时,想让Claude操作浏览器,得为每个工具写一套适配代码。有了MCP,Playwright暴露一套标准化的工具定义,Claude直接调用,中间的胶水代码不用你写。
MCP不替代任何一条技术路线——CDP直控、无障碍树、截图识别,底层该走哪条路线还是走哪条,MCP只是在上面加了一层标准化接口。
选型决策速查
- 调试自己的Web应用:DevTools MCP,29个工具覆盖审计、追踪、网络分析,性能能力最全
- 通用自动化默认选择:Playwright MCP,2026年的标配,29K Star不是白来的
- Coding Agent场景:用@playwright/cli,工具定义从18K Token压到几百
- 爬反Bot检测的网站:Camoufox在C++层面改指纹,配合Crawlee做内容提取
- 大规模并行:Browserbase,功能全、Bug0便宜、支持自然语言控制
- AI原生场景:Stagehand V3架构最新,Browser-AI更轻量
写在最后
6条路线讲完了。工具会不停出新,但底层架构原理就这几条:
- CDP协议是远程控制的基础
- 无障碍树把Token成本压了100倍
- 云浏览器解决环境隔离
- 反检测要在C++层面做才有用
- AI原生路线把选择器维护成本降到了0
这些知识不会过时。下次看到一个新的浏览器自动化工具,花30秒想想它走的是哪条路线、能力边界在哪,心里就有数了。